Diferencia entre DISTINCT y GROUP BY: Entendiendo su Impacto en el Análisis de Datos
En el mundo del análisis de datos, comprender las diferencias entre las cláusulas DISTINCT y GROUP BY es fundamental. Ambos son utilizados para manejar la duplicación de datos en consultas SQL, pero su aplicación y resultados pueden variar significativamente. En este artículo, exploraremos en detalle estas diferencias prácticas, proporcionando ejemplos claros y visuales para una comprensión más profunda.
Este articulo aplica para cualquier gestor de base de datos como SQL Server, Mysql, Postgresql, oracle, entre otros puesto que esto es estandard.
Lógica de cada función DISTINCT y GROUP BY
DISTINCT: La cláusula DISTINCT se utiliza para eliminar filas duplicadas de un conjunto de resultados. Funciona examinando los valores de una o más columnas especificadas y devolviendo solo valores únicos. Por ejemplo:
SELECT DISTINCT columna FROM tabla;
GROUP BY: Por otro lado, GROUP BY se utiliza para agrupar filas que tienen el mismo valor en una o más columnas especificadas y aplicar funciones de agregación como COUNT(), SUM(), AVG(), etc., a los grupos resultantes. Por ejemplo:
SELECT columna, COUNT(*) FROM tabla GROUP BY columna;
Ampliando la comparación entre DISTINCT y GROUP BY:
Vamos a explorar más a fondo estas diferencias con ejemplos concretos:
Ejemplo 1: Datos numéricos
Supongamos que tenemos una tabla de ventas con múltiples entradas para cada producto. Si queremos saber cuántos productos únicos se han vendido, usaríamos DISTINCT :
SELECT DISTINCT producto FROM ventas;
Por otro lado, si queremos saber cuántas unidades de cada producto se han vendido, usaríamos GROUP BY:
SELECT producto, SUM(unidades) FROM ventas GROUP BY producto;
Ejemplo 2: Datos de texto
Imaginemos una tabla de empleados donde algunos nombres aparecen más de una vez debido a múltiples registros. Para obtener una lista única de nombres, usaríamos DISTINCT :
SELECT DISTINCT nombre FROM empleados;
Pero si quisiéramos saber cuántos empleados comparten el mismo apellido, usaríamos GROUP BY:
SELECT apellido, COUNT(*) FROM empleados GROUP BY apellido;
Ejemplos visuales
Las diferencias entre DISTINCT y GROUP BY se vuelven más claras cuando las visualizamos:
Uso de DISTINCT
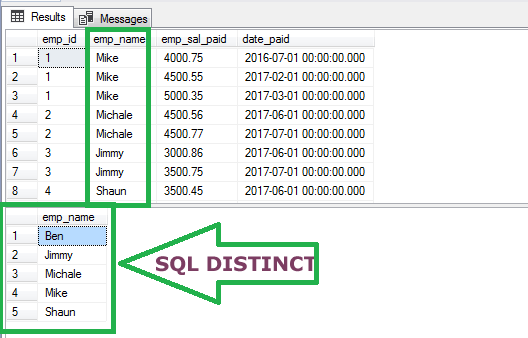
Uso de GROUP BY
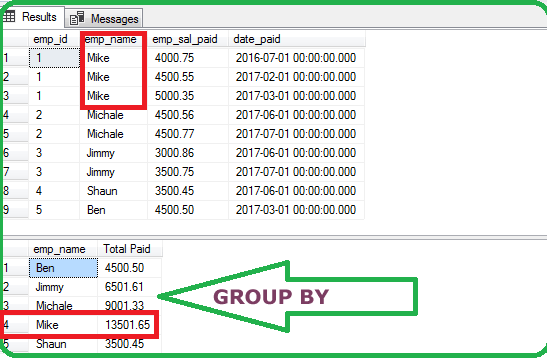
Conclusiones
En resumen, DISTINCT se utiliza para obtener valores únicos de una columna o conjunto de columnas, mientras que GROUP BY se utiliza para agrupar filas basadas en los valores de una o más columnas y aplicar funciones de agregación a estos grupos. Comprender estas diferencias es esencial para un análisis de datos preciso y significativo.
¿Tienes alguna pregunta sobre el este tema en SQL? ¡Déjanos tus comentarios y estaremos encantados de ayudarte!